User:David Mason/P2PU week 1 assignment
For the Peer to Peer University's Open Journalism & the Open Web course week one, Assignment one, I decided to investigate the numbers behind the G20/G8 2010 combined summits in Canada. These summits, particularly the G20, were controversial because of their high costs, lack of transparency, disruptive impact on the city, and heavy-handed and potentially manipulative behaviour by government and police authorities.
In this case, after access to information requests initiated by Dan McTeague, MP, the government released part of the budget, in fax form. The fax became available online, and a message was posted to the Visible Government mailing list and Facebook, asking for people interested in transcribing this data into reusable spreadsheet data, and suggesting the creation of a semantic wiki to make the data reusable and examinable through addition of structure and discourse features, explained below.
A number of individuals helped transcribe the data, which was imported, and discourse features added, along with a number of examples.
The result is highly re-usable, organized information. Because the software is based on the Free Software Mediawiki, the same software used by Wikipedia, it is free to use, can store many entries, and a culture of access is included. All content is malleable and subjective, so having the insights of Wikipedia (neutral point of view, managing content as a group) and the Semantic Web (anyone can say anything about anything) helps work through issues.
All site editing is done via the Web, so anyone can view any page's contents (via the edit or view source tab), site editing history, page edit history (via the history tab), and components of the site, as well as progressively learn how to use and contribute to the site (knowledge which will transfer to similar sites, and which I'd assert is digital literacy past filling in forms). Because the site uses cc-by-sa terms of use, anyone can take the content and use it for their own purposes, as long as they attribute the site and make modified works available under the same terms. All the site components can be exported and re-used easily on any site using Special:Export.
Structured features
While Semantic Mediawiki may seem to focus on the Semantic Web, in this case it is used to make the site easier to use, while making the content re-usable across the site. Therefore queries can be dynamically used in different ways; here is a queried list of current Debatable items.
- Budget numbers are transparently being released from 2010/G20 and G8 Budget
- Government uses precise processes for contracts from 2010/G20 and G8 Budget
- Summit costs were unreasonable from 2010/G20 and G8 Budget
- Summit has biased political motivations from 2010/G20 and G8 Budget
- Handling by authorities was a problem from 2010/G20
- Summit was disruptive from 2010/G20
- How did the faxed information get from McTeague to the G&M and other sites from 2010/G20 and G8 Budget/Budget numbers are transparently being released, User:David Mason/P2PU week 1 assignment
- Discourse systems will be very important to the Web from Integrated semantic discourse systems
- Individuals and companies should be included in discourse systems from Integrated semantic discourse systems
A compressed overview of current discourse (full size):
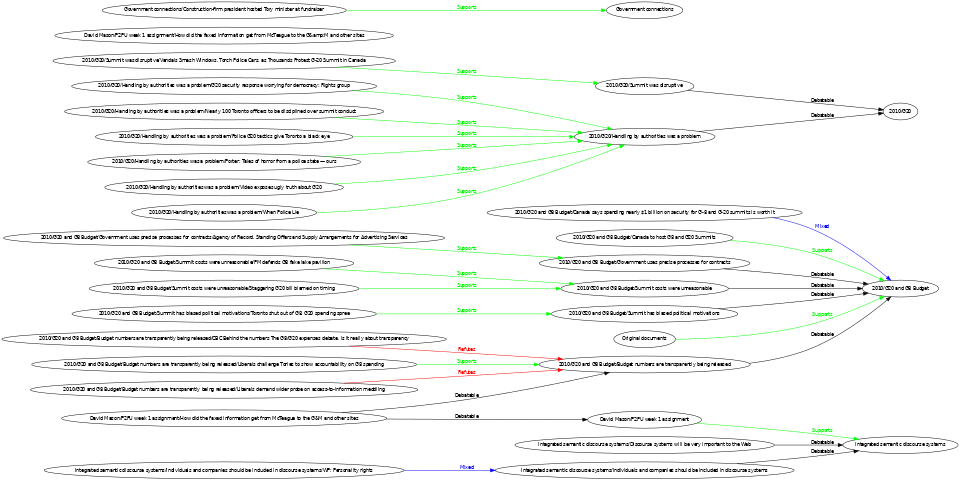
See the procurement exhibit for a particular tool to narrow down cost items by procurement process, and a graph of procurement processes and topics. Ad-hoc queries are also supported.
Since the underlying facilities are in an integrated system, as different visualizations emerge they can also be supported. Ideally the set of visualizations will be consistent, so those accessing the site can learn how to use them as interesting looking and useful tools.
Types of content
The types of content stored in the site are subject (a very general collection of cost items and discourse elements), responsible person, responsible unit, and supplier. An integrated issue system will be explained separately. Procurement process is also separate content, providing the opportunity to precisely describe these processes using process graphs.
Discourse features
This site includes discourse features, which allow assigning a position to subjects. For example, an initial cost item can have another item added with a Debatable position. That item can then have items added with Supports or Refutes positions (you may not see a lot of Position content today, it can be easily added using forms, a good example of a similar populated discourse system is the inspiring Discourse DB).
Use in journalism
This type of system could be used by journalists as an in-house or public database. As related stories are developed, content will be constantly added. Interactive tools can be used for investigation and final display. As part of the Web, journalists can use their authority to work with authorities and "members of the public" for a truly inclusive culture, creating stories out of data and creating comprehensive world views based on facts and positions.
Going forward
Since I'm developing this type of site for several projects, this week I'm investigating a "pipeline" that includes annotation using the GATE software. This could allow importing many Web based pages. While computer software will never have the real understanding of a human, entities such as people, places and dates can be recognized, and sentiments can be read with limited accuracy, therefore ideally people will correct this information to make it more than statistically useful.
The process behind developing this site was interesting to me, and has invoked interest that may spark an ongoing project that can expand to include the structure of governments and connections between government figures and business. The semantic facilities may become more important, allowing the site to interact in a reusable web of information. Hopefully this type of participatory site will become more common, allowing people to constantly learn, organize and re-use information past typical unstructured content today; computer-developed content that is often no better than a typewritten page or fax.
Obviously, while part of a movement, this will take time, and I hope to support and contribute to different groups using these kinds of systems.
If you're interested in participating, please add your name here.
Discourse
Overview of discourse system for journalism
| Source | David Mason |
| Dates | Oct 3, 2010 |
| Project | Integrated semantic discourse systems |
| Topic | Integrated semantic discourse systems |
| Position | Supports |
|